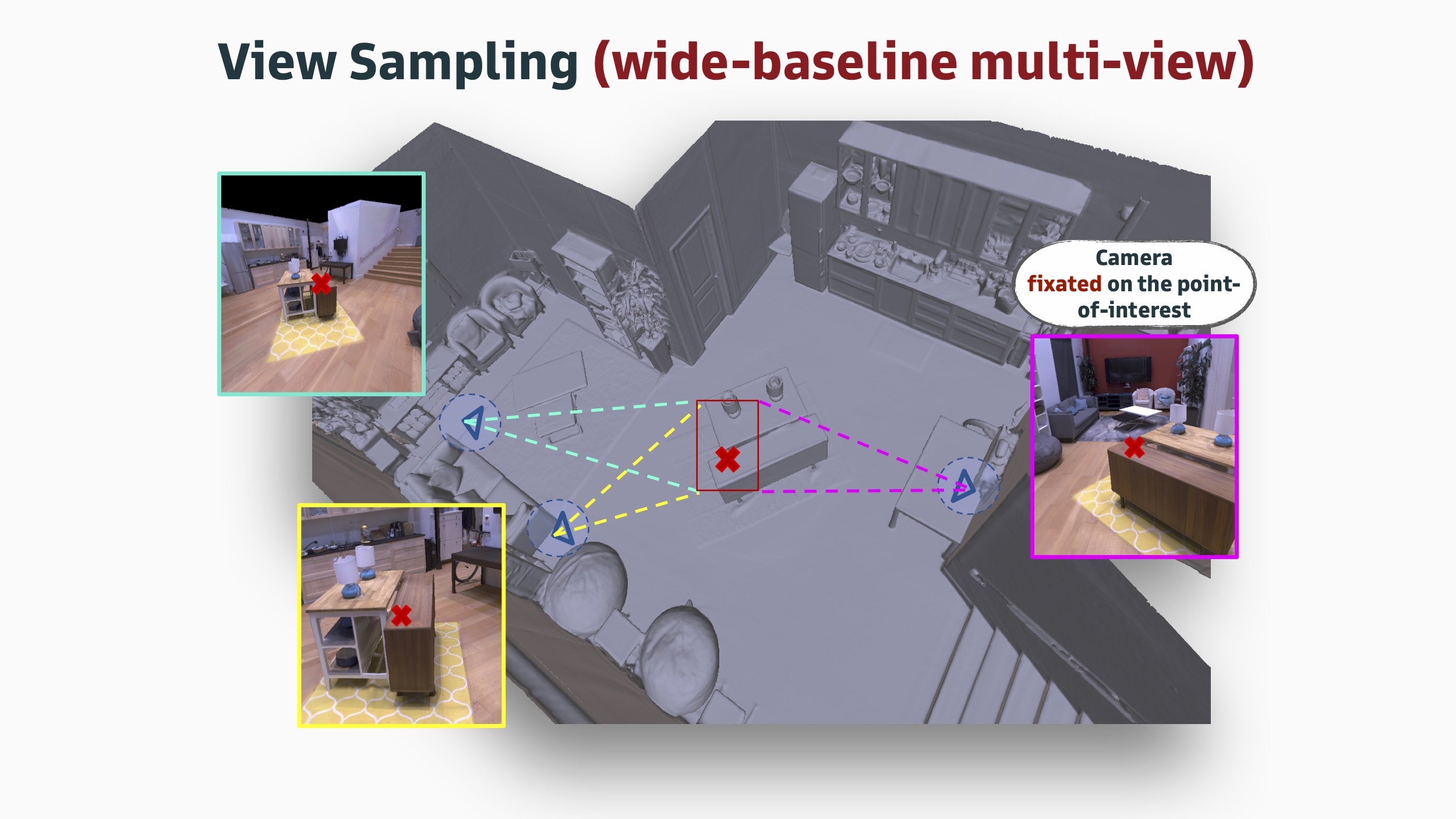
i. A means to train state-of-the-art models
Depth estimation on OASIS images. We trained the method of MiDaS DPT-Hyprid (Ranftl et al. 2021), but only on a starter datset of data output from our pipeline (Omni).
Surface normals extracted from depth predictions. The high-resolution meshes in the starter dataset also seem to produce networks that make more precies shape predictions, as shown by the surface normal vectors extracted from the predictions in the bottom row.
Surface normal prediction on OASIS images. Neither model saw OASIS images during training.
Surface normal prediction on OASIS images. The Omnidata-trained model outperformed the baseline model trained on OASIS data itself.
For a complete list of labels and how they are produced, see the annotator GitHub. To try out the pretrained models, upload an image to a live demo or download the PyTorch weights. Or train your own model using the starter data and dataloaders.
ii. Avenue to a dataset 'design guide'
By capturing as much information as possible and then parametrically resampling that data into 3D images, we can probe the effects of different sampling distributions and data domains. For example, previous research has identified various types of selection bias such as photographer’s bias, viewpoint bias. Choice of sensor (e.g. RGB vs. LIDAR) also affects what information is available to the model.
These choices have real impact. For example, selecting different aperture sizes changes the makeup of images (below and left). In effect, making an dataset more or less object-centric. Play with some of these effects in our dataset design demo or make one yourself with one of the one-line examples in our annotator quickstart.
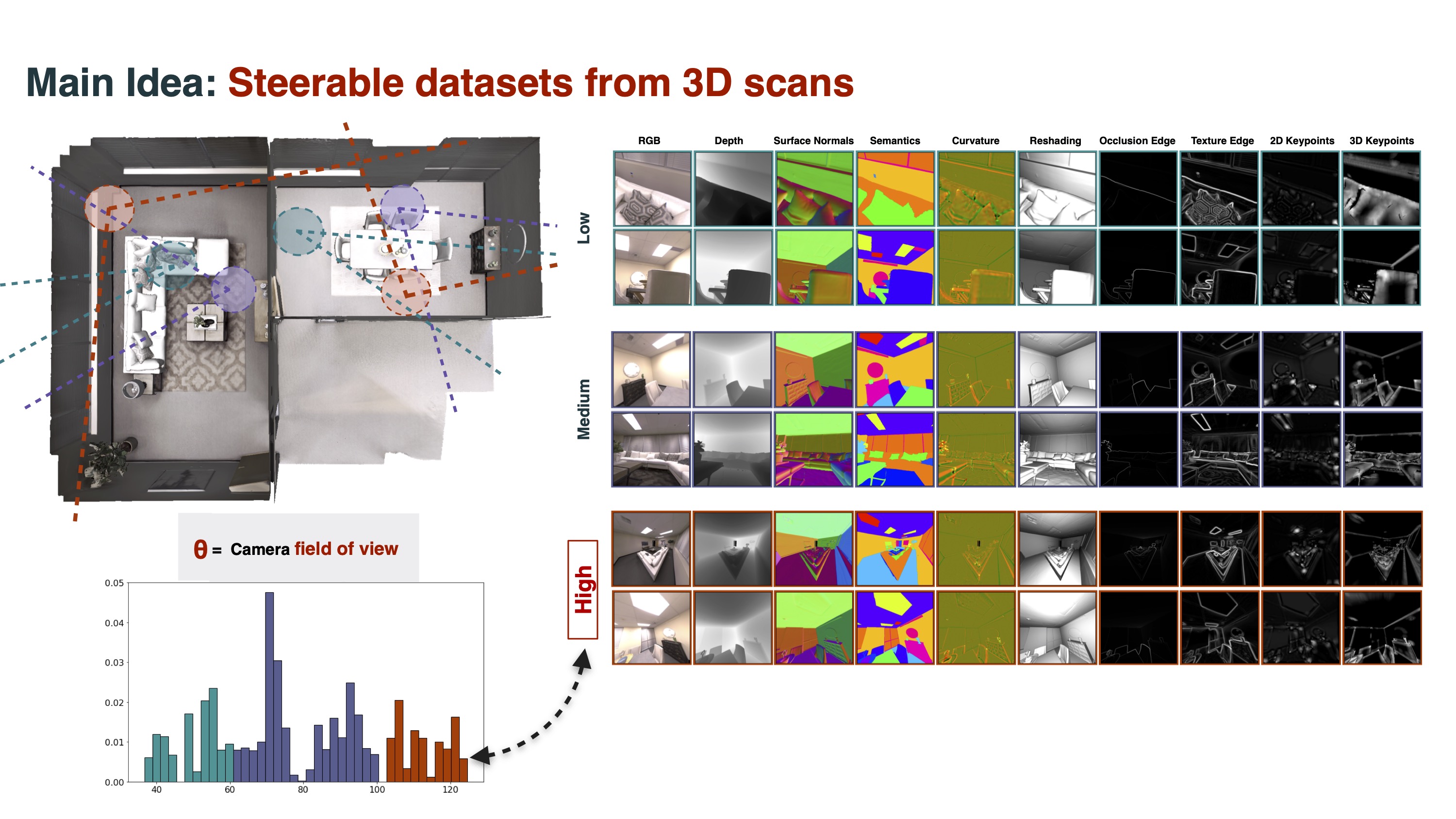
Dataset field-of-view influences image content.
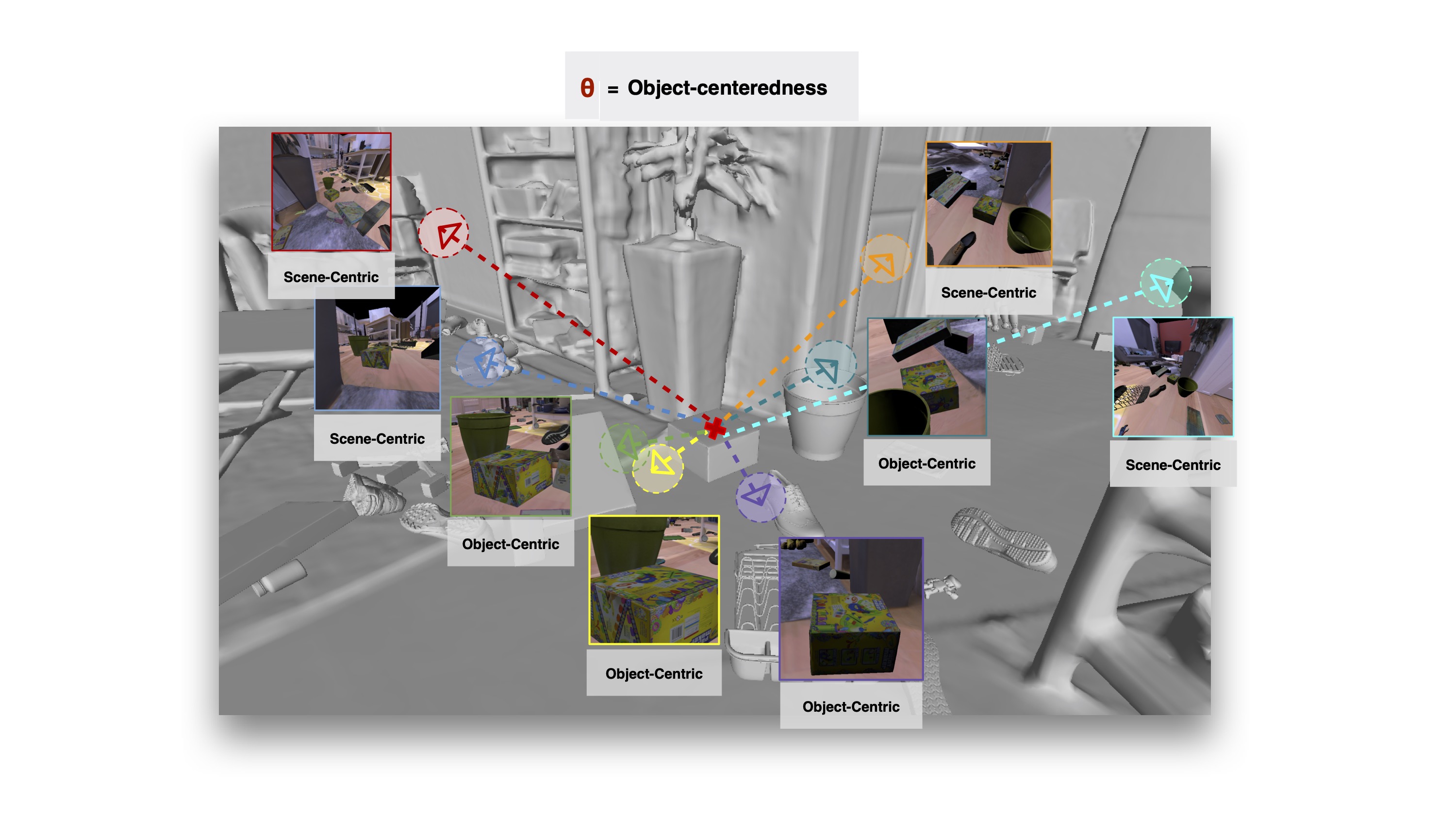
e.g. FoV is correlated with object-level focus.
iii. Matched-pair analysis
ImageNet features are not always best (in vision, in robotics), but determining why an ImageNet classification pretraining is often better than NYU depth estimation pretraining is difficult because ImageNet has no depth labels. So the effect of the pretraining data cannot be separated from the pretraining task.
With the Omnidata pipeline, we can annotate the same dataset for both tasks, in order to determine whether it is the classification pretraining or the image distribution that is doing the heavy lifting. Similarly, the pipeline gives us full control over dataset generation in order to determine the impact of single- vs multi-view training, using correspondences, geometry, camera pose, etc.
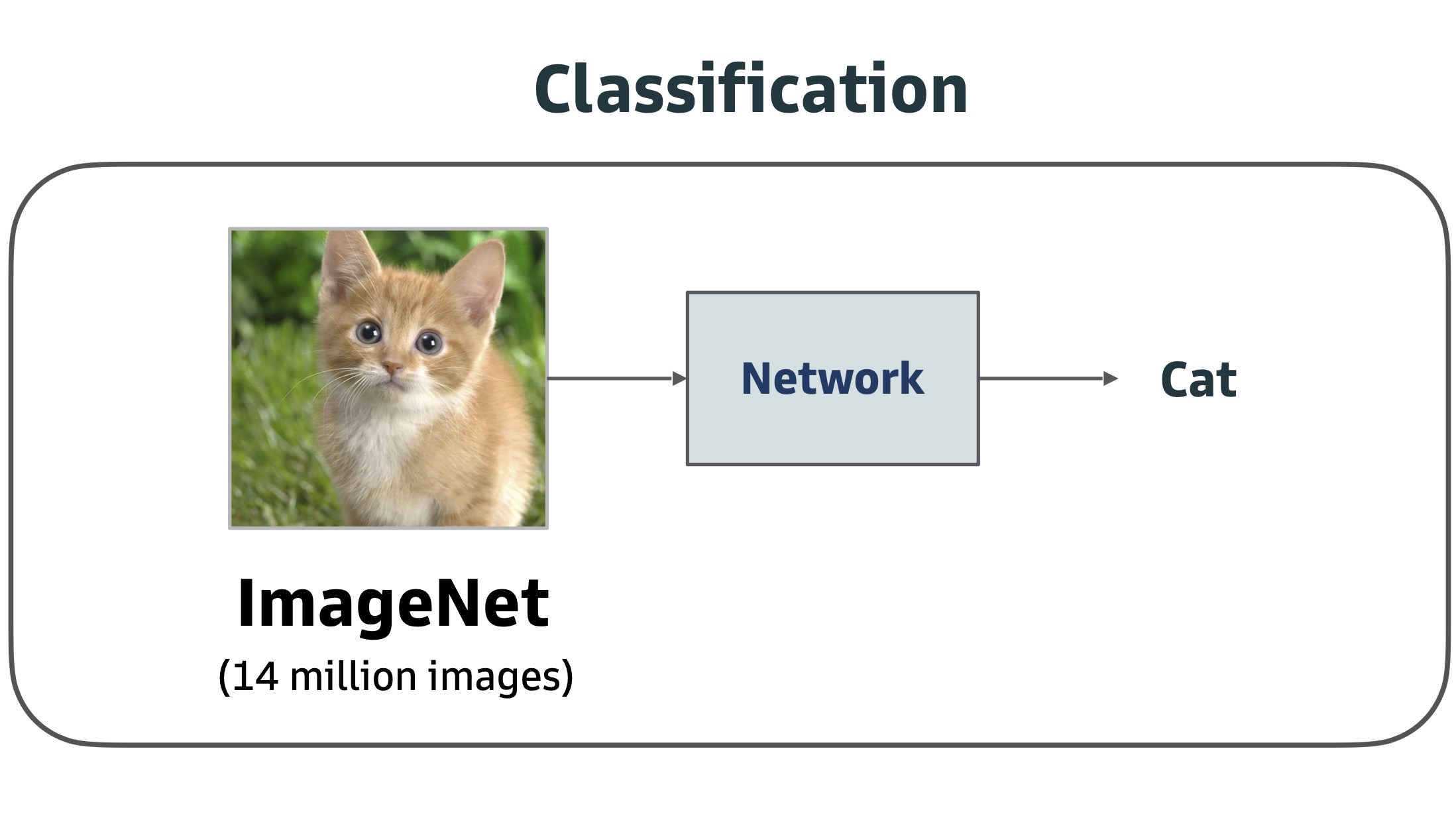

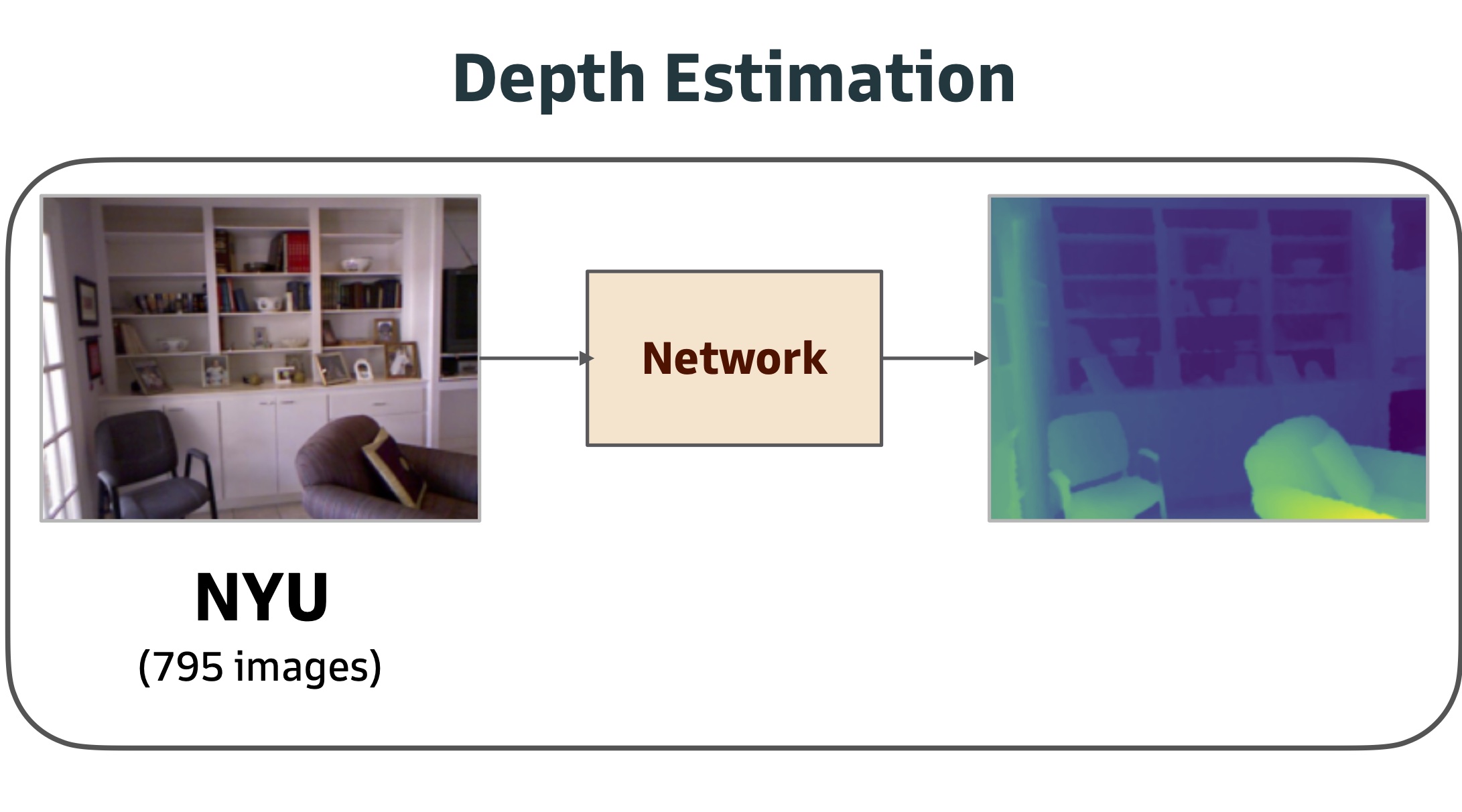
Cross-task comparisons are complicated by confounding factors. Comparing two pretrained models utility for transfer learning is difficult when the two models were trained on disjoint datasets with different parameters: domains, numbers of images, sensor types, resolutions, etc.
iv. Large datasets for even non-recognition spatial tasks
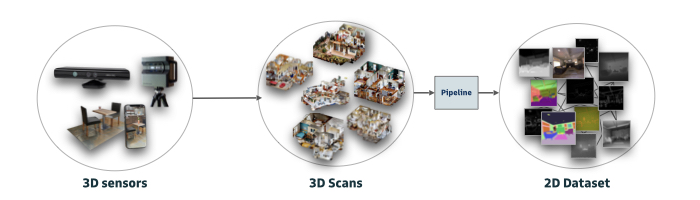
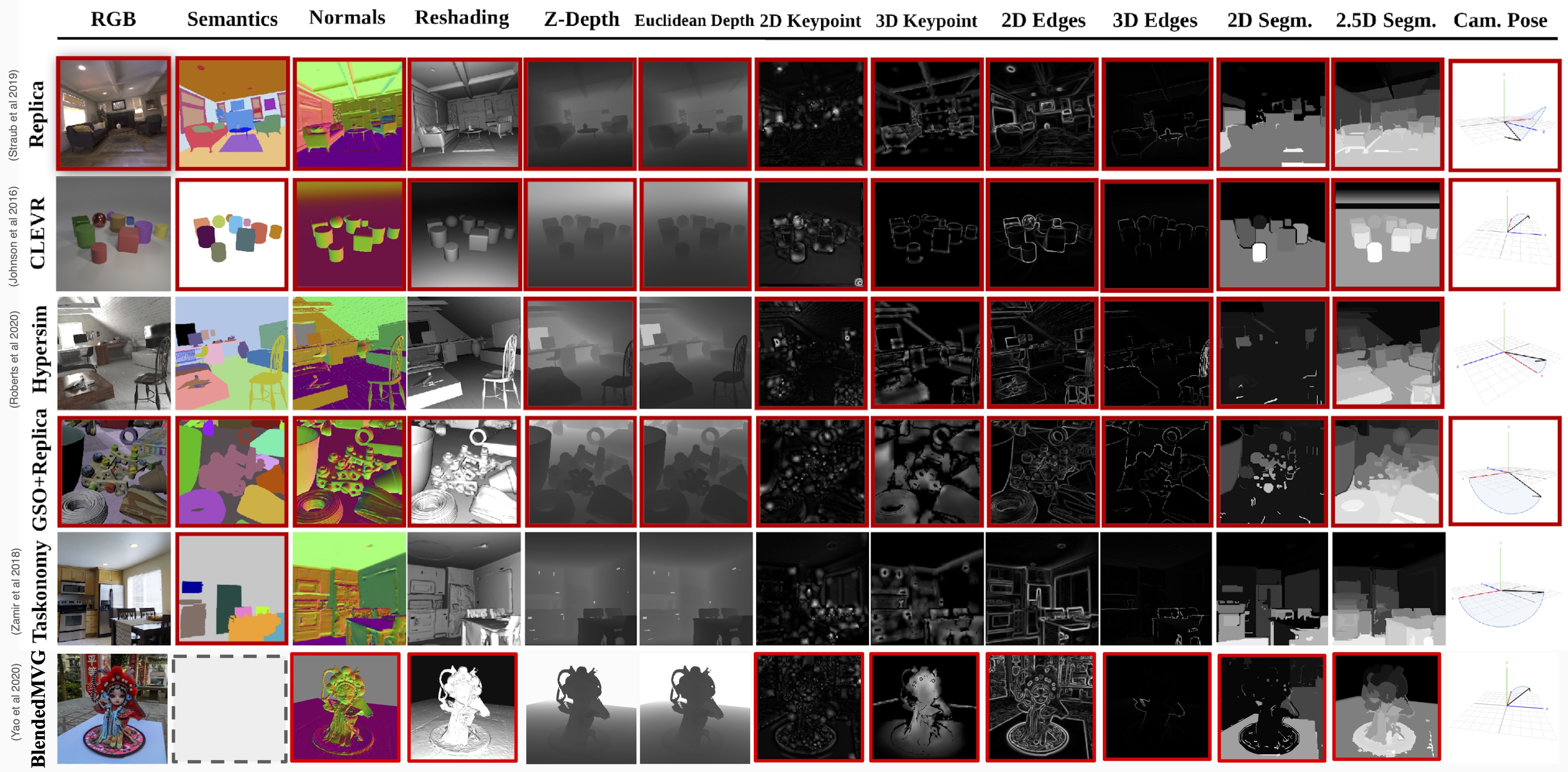
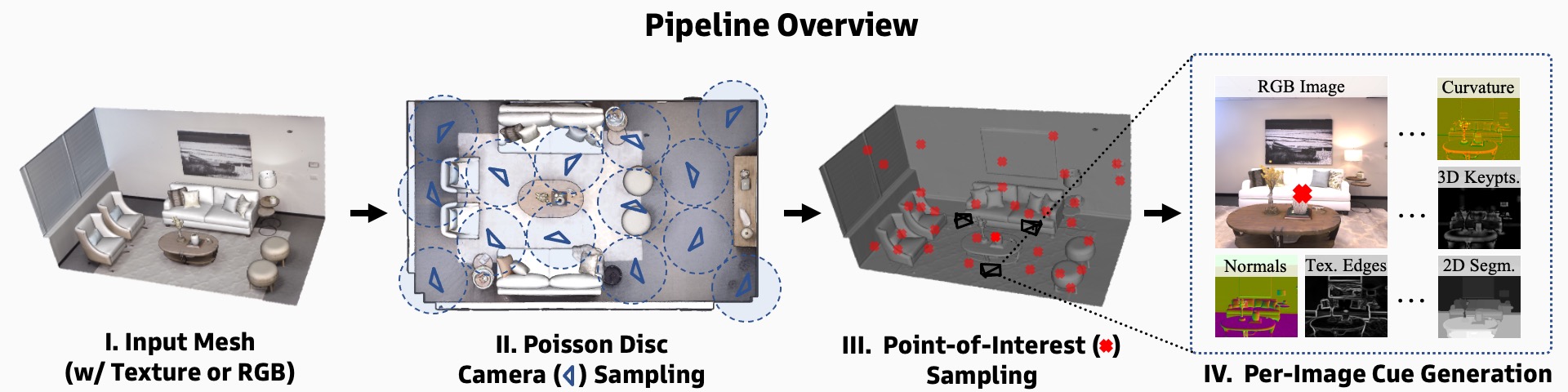
13 of 21 mid-level cues from the Annotator. Each label/cue is produced for each RGB view/point combination, and there are guaranteed to be 'k' views of each point.
For complete information about that starter dataset (including tools to download it), see the data docs.